CSS選擇器可以定位哪些HTML標籤需要套用樣式。主要分成三種,如下:
下方以FJU_website.html為例,分別用谷歌瀏覽器中的開發工具與Python程式在此網頁中取得標題的字串
使用Google Chrome開發人員工具取得CSS選擇器字串
(1) 按F12開啟開發人員工具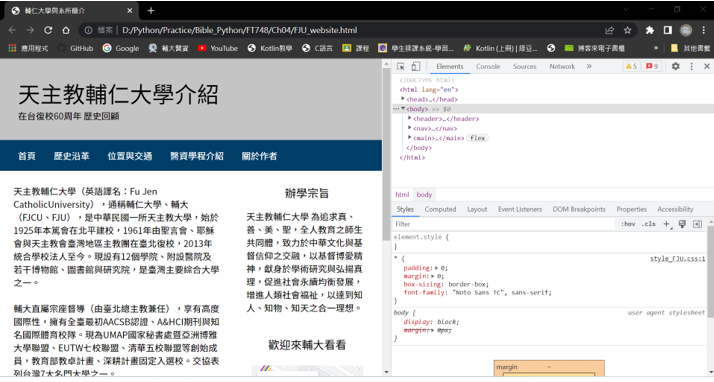
(2) 選取HTML元素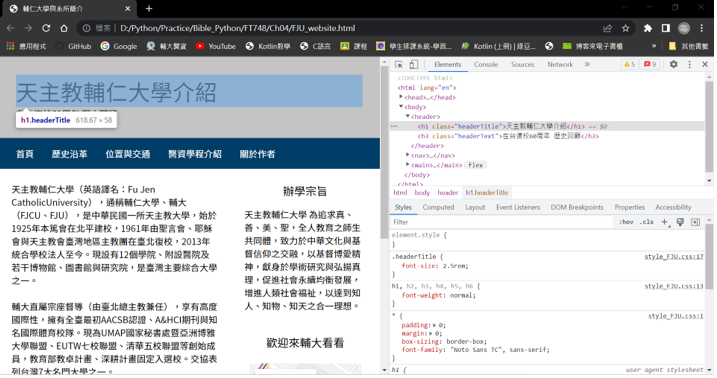
(3) 取得CSS選擇器字串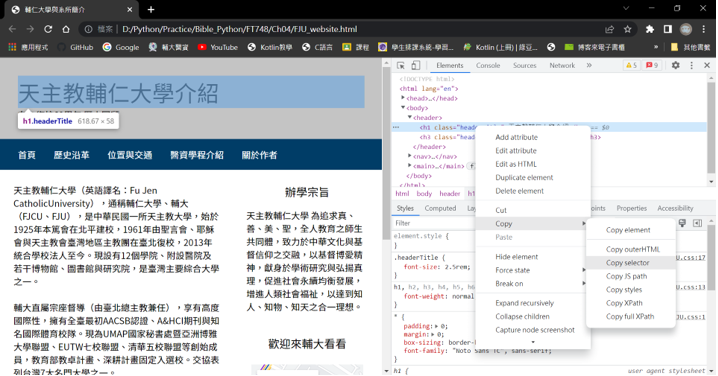
(4) 測試執行CSS選擇器: 使用document.querySelector()函數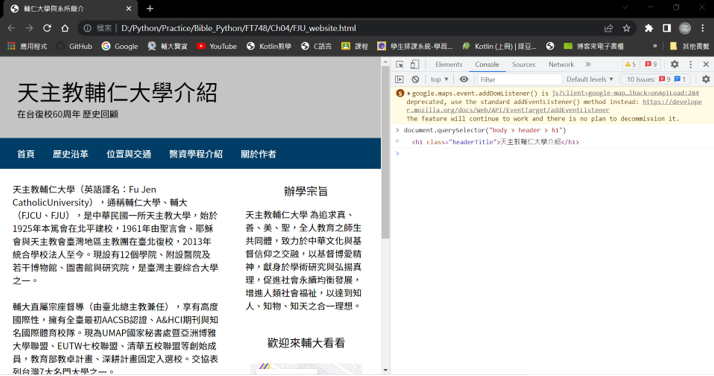
在BeautifulSoup使用CSS選擇器
(1) 找出指定CSS選擇器字串和標籤名稱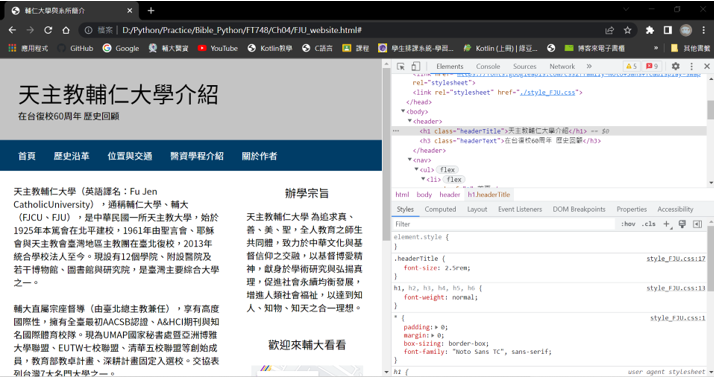
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 找出指定CSS選擇器字串的內容
tag_item = soup.select("body > header > h1")
print(tag_item[0].string)
# 找出指定標籤名稱
tag_title = soup.select("title")
print(tag_title[0].string)

(2) 找出指定標籤下的特定子孫標籤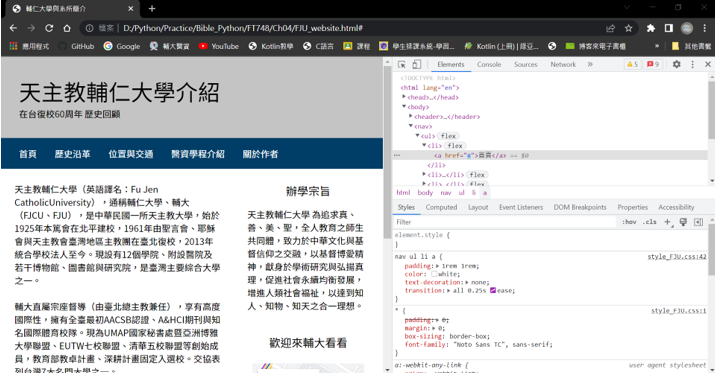
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 找出<title>標籤, 和<li>標籤下的所有<a>標籤
tag_title = soup.select("html head title")
print(tag_title[0].string)
# 找出<li>標籤下的所有<a>標籤
tag_a = soup.select("body nav ul li a")
print(tag_a)

(3) 找出class和id屬性標籤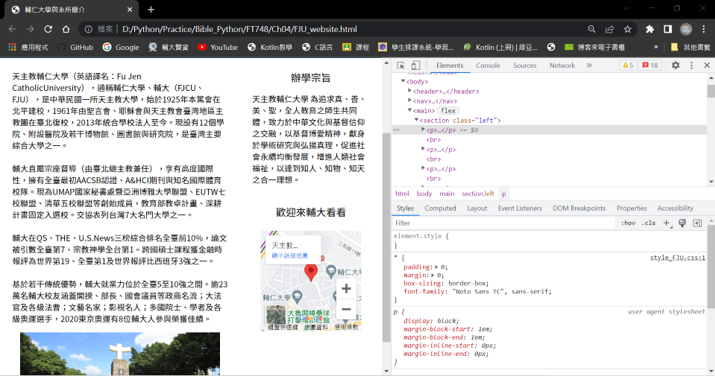
from bs4 import BeautifulSoup
with open("FJU_website.html", "r", encoding="utf8") as fp:
soup = BeautifulSoup(fp, "lxml")
# 找出class的標籤
tag_left = soup.select(".left")
print(tag_left[0].p.string)
# 找出id屬性值的標籤
tag_img = soup.select("#imgFJU")
print(tag_img)